Antlr4系列-Antlr4初体验
Antlr4作为一个强大的语法分析器,被广泛应用于各领域定制领域特定语言(DSL),支持包括Java、Python、C++、JavaScript在内的多种语言。本系列文章没有太多概念性的描述语言,旨在通简单代码,由浅入深,讲解关键部分代码,让读者快速掌握antlr4,理解Antlr4的原理。
一 、环境搭建
1. idea插件安装
在idea的插件商店中搜索antlr4进行安装,或通过
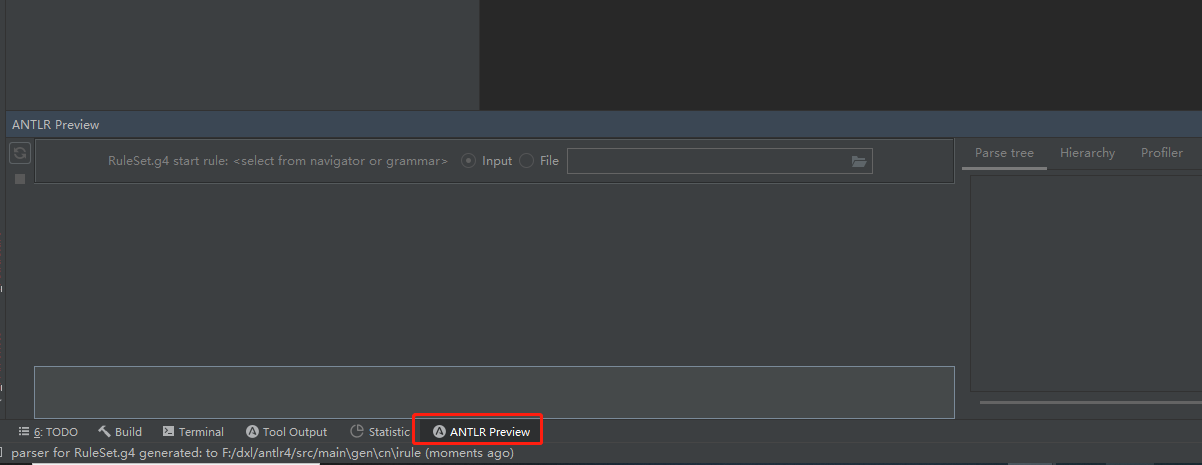
插件下载地址选择对应的版本进行离线安装,安装完成后重启idea,出现以下窗口代表安装成功:
2. 引入依赖包
使用antlr4需要引入运行时的依赖包,新建工程后添加以下gradle引用:
implementation 'org.antlr:antlr4-runtime:4.9'
二、简单的应用
1. 建立语法文件
首先新建一个语法规则文件,antlr4的语法规则文件是以.g4结尾的,新建一个文件指定以.g4结尾即可。在文件中填写以下内容。
grammar RuleSet; //程序名称和.g4名称一致即可
calcu: calcu MUL calcu # mul
| calcu DIV calcu # div
| calcu ADD calcu # add
| calcu SUB calcu # sub
| NUMBER # number
;
WS : [ \t\n\r]+ -> skip ; // ->skip表示antlr4在分析语言的文本时,符合这个规则的词法将被无视
ADD : '+' ;
SUB : '-' ;
MUL : '*' ;
DIV : '/' ;
NUMBER : '-'? [0-9]+('.'([0-9]+)?)? ; // 数字正则
在antlr4中的规则文件一般由两部分组成,小写字母定义的叫做语法,大写字母定义的叫词法,词法一般以固定的字符或正则进行描述,语法中可以使用词法,通常会用一次词法的组合来描述一个语法。
使用【小写字母名称+英文冒号+规则】的方式来定义一个语法。用|来分割多个规则,每个规则后面可以用【#+空格+名称】的方式来为改规则取一个别名,该别名后续会生成一个方法名。别名是可选项,但是需要注意的是如果一个语法下有多个规则时,一旦给其中一个规则定义了别名,剩下的都必须定义,否则生成代码文件时会报错。以上述文件为例,定义了# mul 那么下面的# div 、# add 、# sub、#number别名都是必须定义的。
2. 测试语法的正确性
在idea将光标放到要测试的语法上,右键选择 Test Rule xxx 即可打开语法树界面,在左侧输入文本,右侧会自动将语法解析为语法树,如下:
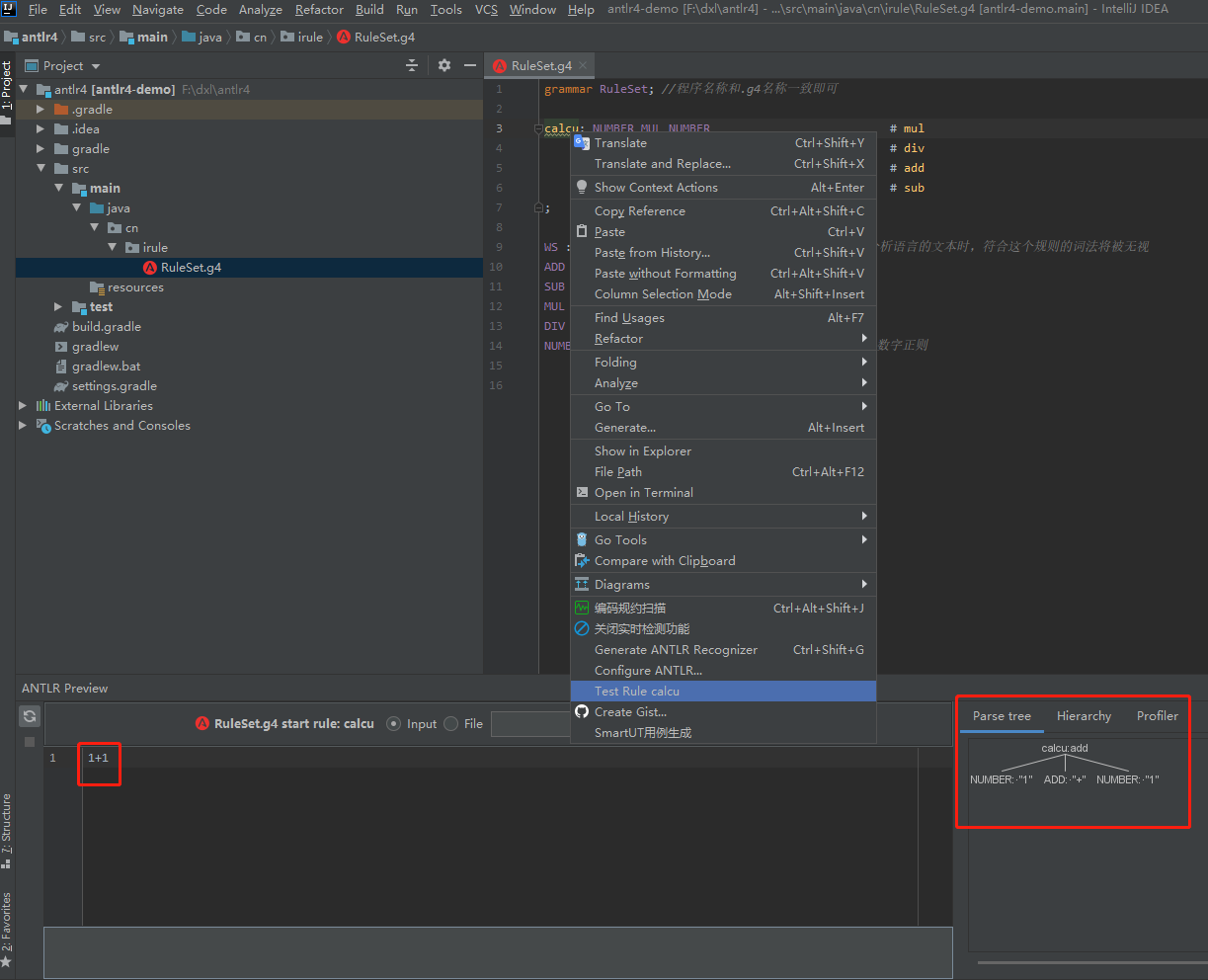
语法测试成功时右侧会将左侧的文本解析成一颗语法树,上图中两个1分别识别出来是NUMBER词法,+识别为ADD词法,整个语法识别为 calcu的add(我们取的别名)规则
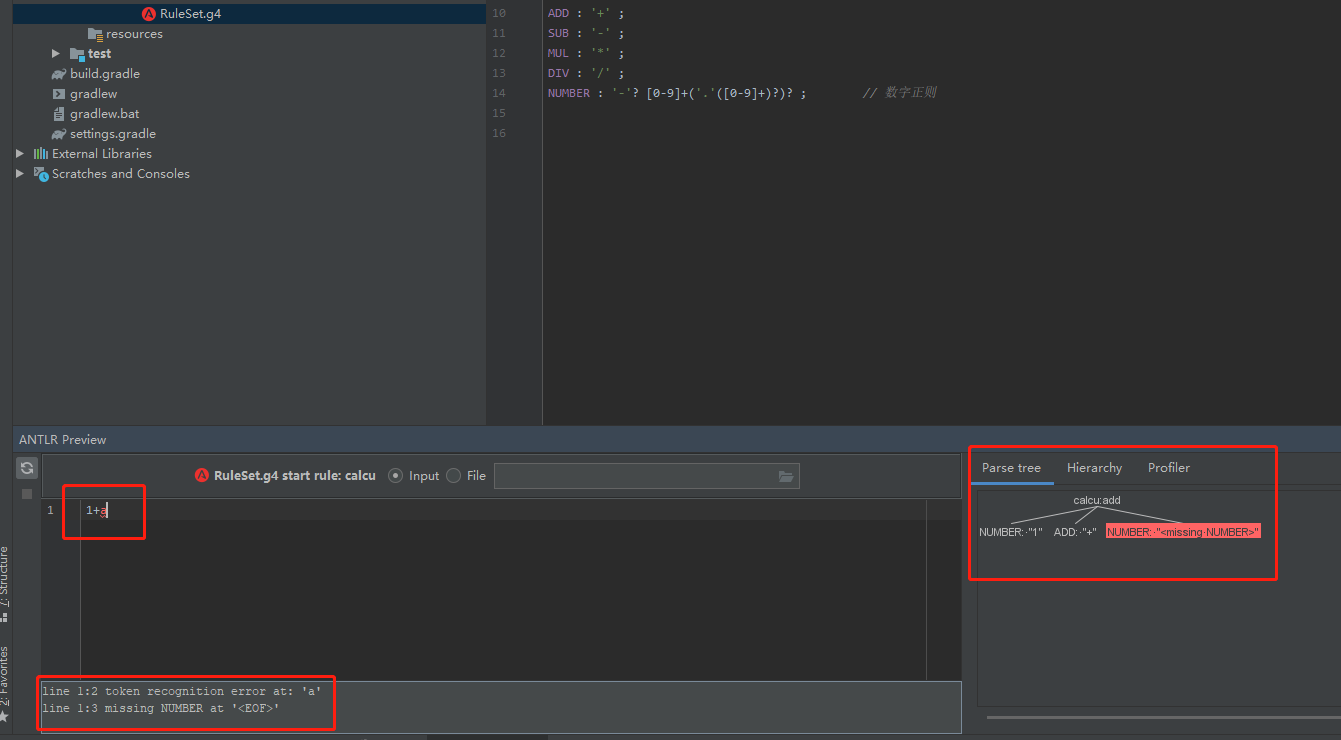
语法测试失败时会有错误提示,提示我们+号的右边缺少了NUMBER,因为我们输入的是1+a,a不满足NUMBER词法的正则。
3. 生成代码文件
在.g4文件中选择右键菜单中的Generate ANTLR Recognizer来生成代码文件,当然在生成之前也可以通过右键菜单中的Configure ANTLR...来对生成代码的输出目录等可配置项进行配置,自行研究即可。
生成好以后将生成的代码复制到工程中,默认的生成路径是.g4文件所在目录的gen目录下,根据所需调整好项目结构,至此.g4文件的使命就已经完成了。最终生成的文件如下:
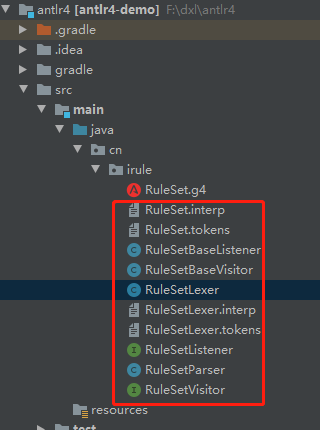
上图中红框中的文件就是自动生成的代码文件,重点需要关注的就是【.g4文件名+BaseListener】和【.g4文件名+BaseVisitor】结尾的两个java文件,这两个文件我们后续需要选择一个继承以后来实现业务逻辑。
4. 实现业务逻辑
antlr4提供了两种方式来实现我们的业务逻辑,访问器和监听器,也就是上面所说的需要关注的两个类,两种实现方式选其一即可。我们这边选择实现访问器来编写我们的业务逻辑代码。
新建一个java类继承上面生成的XXXBaseVisitor接口,重写加减乘除方法,并实现真正的加减乘除功能,如下:
public class MyRuleSetVisitor extends RuleSetBaseVisitor<Double> {
@Override
public Double visitMul(RuleSetParser.MulContext ctx) {
double left = Double.parseDouble(ctx.NUMBER(0).getText());
double right = Double.parseDouble(ctx.NUMBER(1).getText());
return left * right;
}
@Override
public Double visitDiv(RuleSetParser.DivContext ctx) {
double left = Double.parseDouble(ctx.NUMBER(0).getText());
double right = Double.parseDouble(ctx.NUMBER(1).getText());
return left / right;
}
@Override
public Double visitAdd(RuleSetParser.AddContext ctx) {
double left = Double.parseDouble(ctx.NUMBER(0).getText());
double right = Double.parseDouble(ctx.NUMBER(1).getText());
return left + right;
}
@Override
public Double visitSub(RuleSetParser.SubContext ctx) {
double left = Double.parseDouble(ctx.NUMBER(0).getText());
double right = Double.parseDouble(ctx.NUMBER(1).getText());
return left - right;
}
关于泛型:上述代码中
RuleSetBaseVisitor的泛型就代表每次访问一个语法树节点的返回类型,示例是做四则运算,因此指定了返回类型为Double。关于取值:因为在制定规则的时候每个运算符的左右各有一个NUMBER,因此0就代表左边的,1就代表右边的,从左到右按顺序排列,因为NUMBER是正则匹配的数值类型,所以在此处就不需要再进行运行时校验就可以直接转为double型而不用担心运行时报错。
接着编写一个测试类,如下:
public class Test {
public static void main(String[] args) {
String expression = "3 - 1";
calcute(expression);
String expression2 = "3.5 + 1";
calcute(expression2);
String expression3 = "3 * 5";
calcute(expression3);
String expression4 = "10 / 5";
calcute(expression4);
String expression5 = "10 / a";
calcute(expression5);
}
private static void calcute(String expression) {
System.out.println("执行:" + expression);
MyRuleSetVisitor visitor = new MyRuleSetVisitor();
RuleSetLexer lexer = new RuleSetLexer(CharStreams.fromString(expression));
RuleSetParser parser = new RuleSetParser(new CommonTokenStream(lexer));
RuleSetParser.CalcuContext calcu = parser.calcu();
Double result = visitor.visit(calcu);
System.out.println("结果:" + result);
}
}
运行结果如下:
> Task :Test.main() FAILED
执行:3 - 1
结果:2.0
执行:3.5 + 1
结果:4.5
执行:3 * 5
结果:15.0
执行:10 / 5
结果:2.0
执行:10 / a
2 actionable tasks: 2 executed
line 1:5 token recognition error at: 'a'
line 1:6 missing NUMBER at '<EOF>'
Exception in thread "main" java.lang.NumberFormatException: For input string: "<missing NUMBER>"
at sun.misc.FloatingDecimal.readJavaFormatString(FloatingDecimal.java:2043)
at sun.misc.FloatingDecimal.parseDouble(FloatingDecimal.java:110)
at java.lang.Double.parseDouble(Double.java:538)
at cn.irule.MyRuleSetVisitor.visitDiv(MyRuleSetVisitor.java:21)
at cn.irule.MyRuleSetVisitor.visitDiv(MyRuleSetVisitor.java:9)
at cn.irule.RuleSetParser$DivContext.accept(RuleSetParser.java:124)
at org.antlr.v4.runtime.tree.AbstractParseTreeVisitor.visit(AbstractParseTreeVisitor.java:18)
at cn.irule.Test.calcute(Test.java:31)
at cn.irule.Test.main(Test.java:22)
至此,简单的四则运算就已经完成。但是可以看到在执行10 / a时报错了,这是因为在执行前未调用antlr4对输入进行语法校验,后续将继续讲解如何校验以及更为复杂的功能实现。

