最常用的synchronized、volatile和被遗忘的原子类
提起并发和线程安全问题我们通常会想到最常用的synchronized、volatile和各式各样的锁,而原子类却很容易被忽略,但是原子类也有着它的独到之处。今天我们就来聊一聊它们各自的优缺点和原理。文章没有太多概念性的东西,尽量以通俗易懂的语言和简单的代码来摸清它们的原理。
从JAVA内存模型说起
java线程安全问题主要是java的内存机制引起的,我们先来回顾一下java的抽象内存模型: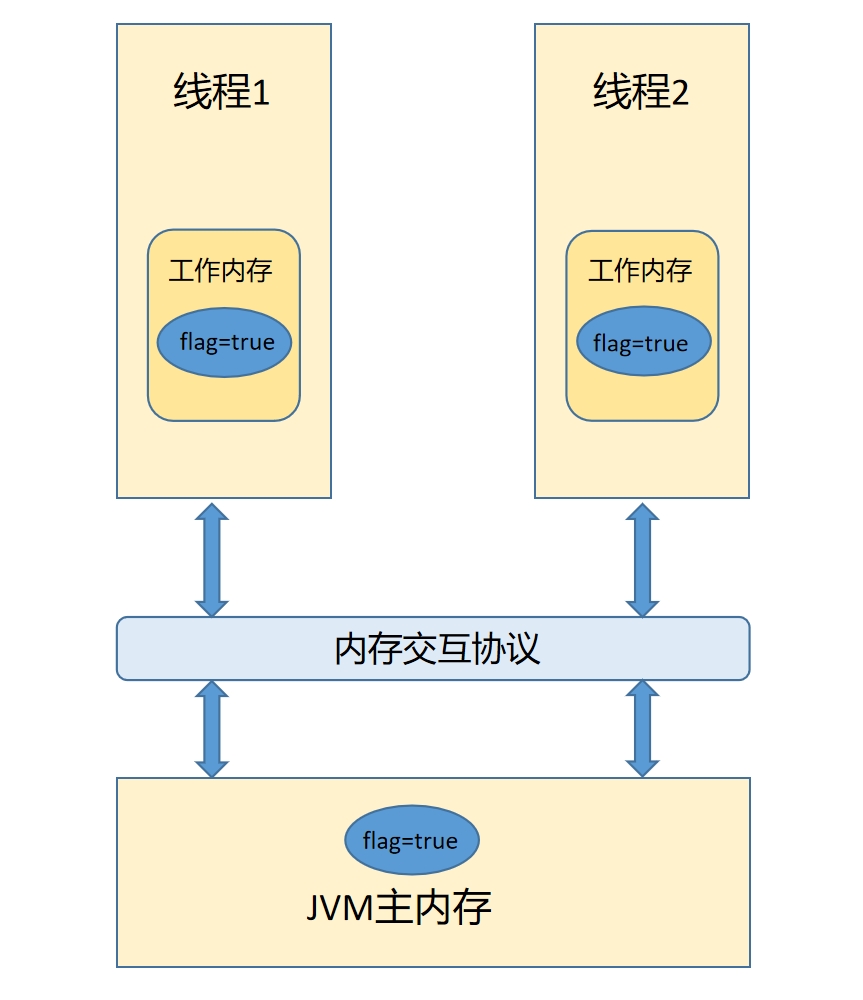
当线程需要操作一个共享变量时,会先从主内存通过内存交互协议读取到线程的工作内存中并写入变量副本,对变量进行操作之后再将变量的值通过内存交互协议写回主内存中。单线程环境下不会有任何问题,但是多线程下就会出现问题,我们可以看到如果线程1和线程2同时从主内存中获取到了共享变量flag=true分别存储在自己的工作内存中,线程1需要使用flag变量时会从工作内存的变量副本拿到变量flag进行操作,将flag的值改为false之后写入主内存,如果此时如果线程2要使用flag的值,会从自己的工作内存,拿到flag的值依然是true,这样就会出现bug。通过代码来感受一下吧!
public class Example {
static class Test {
private boolean flag = true;
public void startRun() {
System.out.println("开始运行");
for (; ; ) {
if (!flag) {
System.out.println("停止运行");
break;
}
}
}
public void changeFlag() {
System.out.println("flag被改变了");
flag = false;
}
}
public static void main(String[] args) throws InterruptedException {
Test test = new Test();
new Thread(test::startRun).start();
Thread.sleep(100);//此处需要sleep一下,防止第二个线程先执行
new Thread(test::changeFlag).start();
}
}
以上代码执行后的结果如下:
开始运行
flag被改变了
可以看出第一个线程一直在运行中并未结束,这就是因为第一个线程是从自己的工作内存中变量副本拿到的值,并不是被第二个线程修改后最新的值。那么如何让第一个线程感知到第二个线程已经将值改变了呢?
关于volatile和synchronized
我们给上述代码中的flag变量加上volatile关键字,改为
private volatile boolean flag = true;
再次运行代码,输出如下:
开始运行
flag被改变了
停止运行
根据运行结果我们可以看出,当第二个线程改变flag值之后第一个线程获取到了flag的最新值,条件成立,结束运行。这就是volatile的可见性。其原理就是当带有volatile关键字的变量被一个线程修改时会立即写入主内存,同时会使其他线程工作内存中该变量的缓存副本立即失效,这样其他需要使用该变量时就会从主内存中重新读取该变量的信息。。我们再将上述代码做点改变,将boolean的flag变量改为int型,第一个线程依然做判断,当flag等于30000时结束第一个线程,另外再用三条线程将flag的值增加到30000。具体代码如下:
public class Example3 {
static class Test {
private volatile int flag = 0;
public void startRun() {
System.out.println("开始运行");
for (; ; ) {
System.out.println("flag=" + flag);
if (flag == 30000) {
System.out.println("停止运行,flag值为:"+flag);
break;
}
}
}
public void changeFlag() {
System.out.println("flag被改变了");
for (int i = 0; i < 10000; i++) {
flag++;
}
}
}
public static void main(String[] args) throws InterruptedException {
Test test = new Test();
new Thread(test::startRun).start(); //线程1
Thread.sleep(100);
new Thread(test::changeFlag).start();
new Thread(test::changeFlag).start();
new Thread(test::changeFlag).start();
}
}
运行结果如下:
flag被改变了
flag被改变了
flag被改变了
flag=0
flag=28102
flag=28102
flag=28102
flag=28102
·
·
·
根据可见代码运行结果我们可以看出,三条线程对flag变量进行累加后并未将值增加到30000,因此第一条线程一直还在运行中。这是因为volatile无法保证原子性,而i++是非原子操作,i++的执行过程包含了三步(读取i值、执行i+1、将i+1的结果赋值给i),flag = false是原子操作,它的执行过程只包含了一步(将false赋值给flag)。那么到底什么是原子性呢?原子在物理中是不可再被拆分的微粒,因此原子性就是指我们的操作是一体的,不能被拆分,不会被线程调度器打断,操作要么不执行,要么全部执行成功。
接下来我们再对上述代码稍作改进,给changeFlag方法加上synchronized关键字。如下:
public synchronized void changeFlag() {
System.out.println("flag被改变了");
for (int i = 0; i < 1000; i++) {
flag++;
}
}
再次运行代码后输出如下:
flag=20000
flag被改变了
flag=20000
flag=26556
flag=28830
停止运行,flag值为:30000
根据以上结果我们可以发现后面三条线程成功将值flag值增加到了30000。这是因为synchronized对整个方法加了锁,只有当一个线程执行完毕释放锁,另一个线程拿到锁之后才能继续执行方法,因此在执行过程中不会被线程调度器打断,保证了方法中操作的原子性。上述示例synchronized是加到方法上的因此是整个方法具有原子性,如果是同步代码块,原理也一样,同步代码块中的操作同样具有原子性。那么synchronized同步方法和同步代码块能不能保证可见性呢?根据我们刚才讲的原理,synchronized同步方法和同步代码块在一个线程执行完成后另一个线程才能执行,当一个线程执行完成后该线程修改的变量会立即写入主内存,因此另一个线程访问时拿到的是变量的最新状态,因此,synchronized可以保证变量的可见性。
关于指令重排
接下来讲一下指令重排,其实简单的来说就是在单线程环境下你所写的代码满足一系列规则的情况下,编译器和执行器为了提高性能会对指令进行重新排列,也就是说你的代码不一定按照你所写的顺序执行。但是要保证无论指令怎么重排序,单线程下的执行结果都不能被改变,这也就是所谓的as-if-serial语义。我们还是通过代码来进行说明,如下:
public class Example4 {
static class Test {
int a = 1; // 1
int b = 2; // 2
int c = a + b; // 3
boolean flag = false;
public void changeFlag() {
a = 3; // A
b = 4; // B
flag = true; // C
}
public void calculate() {
if (flag) { // D
int i = a * b; // E
if (i != 12 ) { // F
System.out.println("i="+i);// G
}
}
}
}
public static void main(String[] args) {
for (; ; ) {
Test test = new Test();
new Thread(test::changeFlag).start();
new Thread(test::calculate).start();
}
}
}
上述代码粗略看没什么问题,但是在长时间执行以后输出结果如下:
> Task :Example4.main()
i=6
上述代码中我们在Test类中定义了两个方法,在main方法中使用两个线程分别调用两个方法,加入死循环是因为该结果出现概率极低,为了多次执行,可以忽略。上面代码正常情况下如果第一个线程先执行第二个线程后执行,那么结果应该是注释D条件成立,注释E执行i结果为12,注释F不成立,打印不执行。如果是第二个线程先执行,第一个线程后执行,那么结果应该是D条件不成立,后续结果不执行,也不会打印。那么为什么会打印出i=6呢?这就是因为出现了指令重排。changeFlag方法中的代码执行顺序变成了A->C->B,当第一个线程执行完注释A给a变量赋值为3,将a变量写回主内存,执行完注释C,将flag变量赋值为true,写回主内存,还没来的及执行注释B时,第二个线程执行了注释D和注释E两步。这就造成了i的结果变成了6,注释F条件成立,打印了i=6。
虽然指令重排是编译器和处理器的事情,且指令重排引发bug的概率也极低,但在编程中再低的概率都会出现是铁定律。因此我们还是得掌握哪些情况下指令不会被重排,那些情况下会被重排。有数据依赖关系的指令不会被重排。还是以上述代码为例:注释3中的变量c依赖了注释1中的变量a和注释2中变量c,因此注释3指令不会在注释1和注释2之前执行。但是注释2中没有依赖注释1的变量,所以注释1和注释2就有可能发生指令重排。这就是数据依赖。注释D和注释E中的代码存在控制依赖,flag条件成立,才会执行执行注释E代码。但是这种控制依赖是允许指令重排的,注释E中a*b的结果会先重排序缓冲的硬件缓存中,条件flag成立时才会赋值给变量i,所以不会造成问题。
理解了指令重排我们再回头看一下上述缺陷如何修复。有两种方案:
- 给flag变量添加
volatile关键字改为volatile boolean flag = false;。volatile还有一个特性就是可以设置内存屏障,禁止指令重排,保证有序性。关于内存屏障这里不再展开讲解,有兴趣的小伙伴可以自行查阅。我们只需要记住volatile变量禁止指令重排的范围即可。
- 禁止读操作及该操作以后的的任何读、写操作进行指令重排。
- 禁止写操作及该操作以前的的任何读、写操作进行指令重排。
我们还是以上述代码为例进行说明添加
volatile以后关键代码如下:int a = 1; // 1 int b = 2; // 2 int c = a + b; // 3 volatile boolean flag = false; //4 int d = 3;// 5 int e = 4; // 6 public void changeFlag() { a = 3; // A b = 4; // B flag = true; // C } public void calculate() { if (flag) { // D int i = a * b; // E if (i != 12 ) { // F System.out.println("i="+i);// G } } }为了方便说明我们添加了注释5和注释6两行。注释4是volatile变量flag的写操做,在它之前读写操作都不会被重排,在它之后的操作可能会被重排。所以执行顺序是1->2->3->4->5->6或者1 ->2->3->4->6->5。注释C是flag的写操作,因此注释ABC的执行顺序只能是A->B->C。这样就可以解决刚才示例中的问题。接着看注释DE,注释D中flag是读操作,在它之后的指令不会被重排,注释E和F有数据依赖本身就不会被重排,因此DEF的执行顺序只能是D->E->F。
- changeFlag方法添加
synchronized关键字,变为同步方法。synchronized同步方法和同步代码块虽然允许指令重排但是内存模型保证了它执行结果和按顺序执行结果是一致的。简单来说就是前面的讲过的指令重排的原则,单线程下无论如何指令如何重排都会保证结果的正确性,而方法添加synchronized关键字之后只能一个线程执行,相当于单线程执行changFlag方法,因此synchronized保证了程序的执行的有序性。
通过以上示例我们已经对volatile和synchronized的特性有了一定的了解,接下来我们做一个简单总结:
- volatile并非一个锁机制,它通过内存模型的一些特性来保证了可见性和有序性,是一种轻量级的同步机制,但是它不能保证原子性,因此在单独使用它的时候需要慎重,只能用于一些原子操作中。
- synchronized是一中锁机制,通过加锁的方式让线程独占资源,可以保证可见性、原子性和有序性。虽然JDK6对它进行了优化可以根据并发量进行锁升级(无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态),但是由于它升级以后很难降级,我们要慎用,使用的时候尽量少的在方法上加锁,而是使用同步代码块锁一些存在线程安全的操作。
被遗忘的原子类
上面的示例我们可以看出synchronized锁太重,影响程序性能,volatile又不能保证原子性,只能在特定场景使用。那么有没有一种方法既能保证原子性,又能减少性能开销?我们还是从java内存模型来分析,synchronized是在一个线程拿到锁之后,释放锁之前其他线程都不能进行操作。大家都知道出现线程不安全只是小概率事件,那么能不能让所有线程都能拿到变量进行操作,在赋值的时候做一个判断,如果值没有改变,那就直接写入,如果值改变了那就重新操作一次,直至成功。原子类就是基于这种方式实现的,接下来我们来了解一下原子类。原子类位于java.util.concurrent.atomic包下,从JDK5开始被引入进来,最初有12种原子类,JDK8又引入4种,目前总共有16种。
接下来我们还是回到Example3的示例,之前我们通过给changeflag添加synchronized的方式解决了flag在被三条线程同时调用后未自增到30000的问题,现在我们换一种方式,使用原子类AtomicIntegerFieldUpdater来解决i++不是原子操作的问题。修改后的代码如下:
public class Example3 {
static class Test {
private volatile int flag = 0;
AtomicIntegerFieldUpdater<Test> updater = AtomicIntegerFieldUpdater.newUpdater(Test.class, "flag");
public void startRun() {
System.out.println("开始运行");
for (; ; ) {
System.out.println("flag=" + flag);
if (flag == 30000) {
System.out.println("停止运行,flag值为:"+flag);
break;
}
}
}
public void changeFlag() {
System.out.println("flag被改变了");
for (int i = 0; i < 10000; i++) {
updater.addAndGet(this,1);
// flag++;
}
}
}
public static void main(String[] args) throws InterruptedException {
Test test = new Test();
new Thread(test::startRun).start(); //线程1
Thread.sleep(100);
new Thread(test::changeFlag).start();
new Thread(test::changeFlag).start();
new Thread(test::changeFlag).start();
}
}
运行代码,结果如下:
flag=28385
flag=28511
flag=28661
flag=28802
停止运行,flag值为:30000
通过以上结果我们可以看出flag的值被成功的增加到了30000,那么原子类又是如何保证操作具有原子性呢?我们通过源码来进行分析。我们先来看AtomicIntegerFieldUpdater的addAndGet方法:
public int addAndGet(T obj, int delta) {
int prev, next;
do {
prev = get(obj);
next = prev + delta;
} while (!compareAndSet(obj, prev, next));
return next;
}
该方法有两个参数,第一个是对象实例,第二个是要增加的值,方法内部定义了两个参数,第一个是prev指的是当前值,next指的是操作之后的新值,整个方法只做了一件事,就是不停的进行获取新值,重新计算,直到调用compareAndSet返回true后跳出循环,返回最新计算过之后的值,这就是所谓的自旋。再来看看compareAndSet方法:
public final boolean compareAndSet(T obj, int expect, int update) {
accessCheck(obj);
return U.compareAndSetInt(obj, offset, expect, update);
}
只做了2步操作第一步是检查了传入的对象是不是初始化AtomicIntegerFieldUpdater时指定的class的实例,重点是第二步U.compareAndSetInt(obj, offset, expect, update);,我们先来看看U的定义:private static final Unsafe U = Unsafe.getUnsafe();。至此其实我们已经明白了它的原理,Unsafe类的compareAndSetInt方法是一种CAS操作,它从硬件层面保证了操作的原子性,操作成功返回true,失败则返回false。
讲到这里熟悉CAS的小伙伴可能会说CAS操作存在ABA问题,ABA问题简单的来说就是:线程1获取了变量a的值是A,线程2将变量a的值改为了B,线程3将又将a的值改成了A,这时候线程1在进行CAS操作时发现线程变量a的值还是A会认为它没有被改变,直接进行操作并返回成功。如果是引用类型的变量后续再操作旧的变量,内存地址就会不存在,从而发生错误。解决ABA问题的方法就是为每次操作增加版本号,不但要判断值有没有变化,而且还要判断版本号有没有变化。官方已经为我们提供了解决方案,AtomicStampedReference和AtomicMarkableReference两个引用类型的原子类就解决了ABA问题。它们的区别如下:
- AtomicStampedReference使用了int型作为版本号。
- AtomicMarkableReference使用了boolean型作为版本号。
另外,有的小伙伴在查看源码的时候可能会发现有的原子类中并未使用Unsafe,这是Unsafe类从JDK9开始已经被逐渐弃用,java.util.concurrent包下的大部分Unsafe操作都被VarHandle替代(如:AtomicLongArray、AtomicReference等),但VarHandle并未实现全部的Unsafe方法,因此,部分类中还在使用,本示例中的AtomicIntegerFieldUpdater就是如此。
其他的原子类也是同样的原理,这里就不再一一讲解,使用过程中可以自行在java.util.concurrent.atomic包下去查看,各个类的方法也相对比较简单。
接下来我们对原子类做个简单总结:
- 原子类是一种无锁同步机制,基于CAS操作从硬件层面保证了操作的原子性,但它不能保证可见性,因此它需要和volatile关键字搭配使用。除引用类型的原子类外其他的原子类只能保证单个变量操作的线程安全,如果实际开发中涉及到多变量,需要将它们封装到一个类中,使用引用类型的原子类进行操作,或者使用其他锁机制。
以上就是synchronized、volatile和原子类的全部内容,记住了它们的特性,在使用中结合实际的业务场景就可以很好的搭配使用它们。

